2/2566 FRA500/625 Human-Robotics Interface – narongrat.usir
วัตถุประสงค์
- เพื่อนำภาษามือของคนพิการทางได้ยินนำไปสั่งงานหุ่นยนต์ในท่าทางต่างๆ
- เพื่อศึกษา interface ระหว่าง มนุษย์ กับ หุ่นยนต์
System Scenario
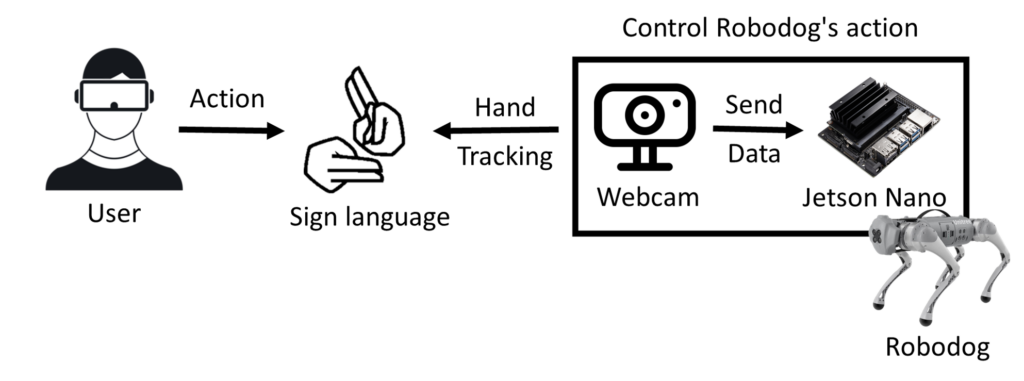
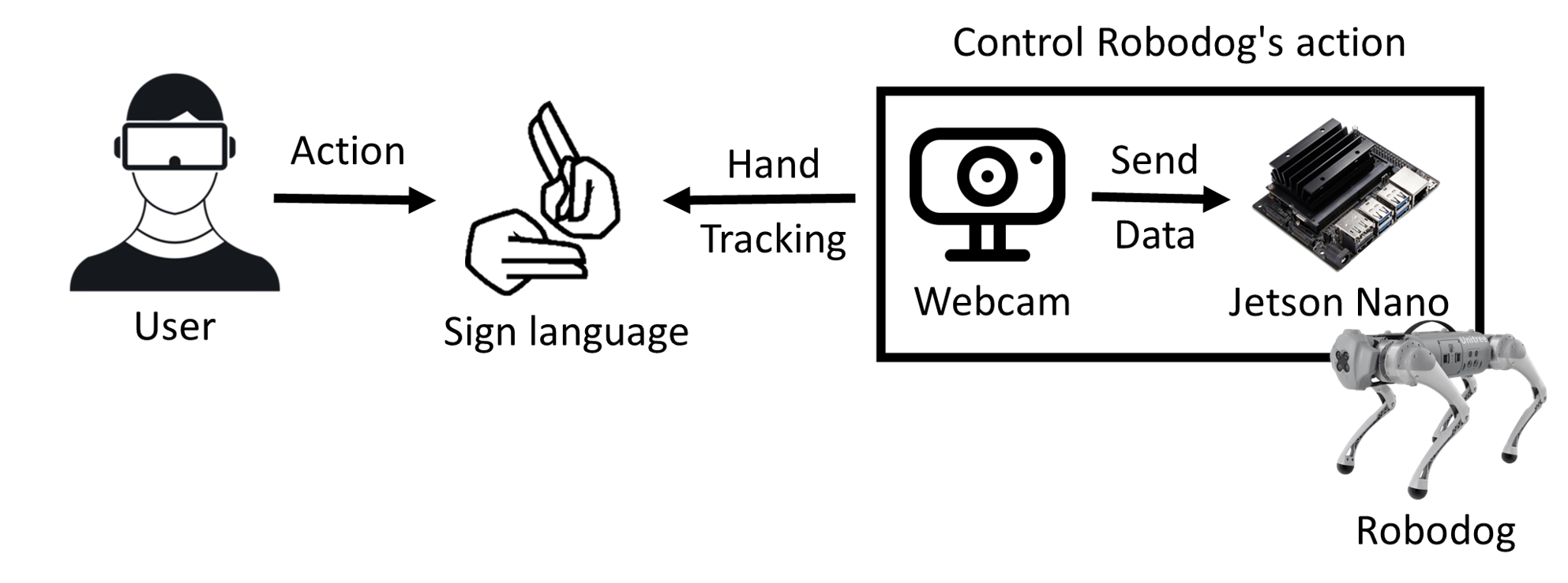
User แสดงท่าทางภาษามือ ไปที่ Webcam เพื่อ Hand tracking จากนั้น Webcam จะส่งท่าทางภาษามือ ไป Jetson Nano เพื่อแยกแยะว่าท่าทางภาษามือที่ส่งไปเป็นท่าอะไร จากนั้นก็จะควบคุม Robodog ให้ทำท่าทาง ตามภาษามือ ที่เรา Program ไว้
เก็บข้อมูลท่าภาษามือจากการเยี่ยมโรงเรียนโสตศึกษาทุ่งมหาเมฆ
ได้ไปสำรวจ User (บุคคลพิการการได้ยิน) เพื่อเก็บข้อมูลลักษณะท่าทางของภาษามือที่จะนำมาใช้ในการสั่ง Robodog Go1 EDU ได้ดังนี้
- นั่ง

- หมอบ หรือ รอ

- ยืน

- เดินซ้าย
- เดินขวา
- เดินหน้า
- เดินถอยหลัง
- หยุด

- กระโดด

ผลจากการไปสำรวจมา สังเกตได้ว่าลักษณธมือจะอยู่ที่ระดับอก ทำให้ไม่เหมาะสมกับการนำ Hololen2 มาใช้ นอกจากนี้ลักษณะท่าทางที่ใช้แม้มีความหมายเหมือนกัน แต่การทำท่าไม่เหมือนกัน
ออกแบบโปรแกรมภาษามือ
Hand Landmark Model

Hand Landmark Model จะตรวจจับ ตำแหน่งจุดสำคัญของพิกัดมือและข้อมือ 3 มิติ 21 จุดภายในบริเวณมือที่ตรวจพบ
Configuration Options
- static_image_mode : หากตั้งค่าเป็นเท็จ โซลูชันจะถือว่าภาพที่อินพุตเป็นสตรีมวิดีโอ หากตั้งค่าเป็นจริง การตรวจจับมือจะทำงานบนทุกภาพที่นำเข้า ค่าเริ่มต้นเป็นเท็จ
- max_num_hands : จำนวนมือสูงสุดที่จะตรวจจับ ค่าเริ่มต้นเป็น 2
- model_complexity : ความซับซ้อนของโมเดลจุดสังเกตบนมือ: 0 หรือ 1 ค่าเริ่มต้นเป็น 1
- min_detection_confidence : ค่าความเชื่อมั่นขั้นต่ำ ([0.0, 1.0]) จากแบบจำลองการตรวจจับมือจึงจะถือว่าการตรวจจับสำเร็จ ค่าเริ่มต้นเป็น 0.5
- min_tracking_confidence : ค่าความเชื่อมั่นขั้นต่ำ ([0.0, 1.0]) จากแบบจำลองการติดตามจุดสังเกตสำหรับจุดสังเกตมือที่จะถือว่าติดตามได้สำเร็จ ค่าเริ่มต้นเป็น 0.5
Output
- multi_hand_landmarks : การรวบรวมมือที่ตรวจพบ/ติดตาม โดยแต่ละมือจะแสดงเป็นรายการจุดสังเกตของเข็มนาฬิกา 21 จุด และจุดสังเกตแต่ละจุดประกอบด้วย x, y และ z x และ y ถูกทำให้เป็นมาตรฐานเป็น [0.0, 1.0] ตามความกว้างและความสูงของภาพตามลำดับ z แสดงถึงความลึกของจุดสังเกตโดยความลึกที่ข้อมือเป็นจุดกำเนิด และยิ่งค่ามีค่าน้อย จุดสังเกตก็จะอยู่ใกล้กล้องมากขึ้น
- multi_hand_world_landmarks : การรวบรวมมือที่ตรวจพบ/ติดตาม โดยแต่ละมือจะแสดงเป็นรายการจุดสังเกตของเข็ม 21 เข็มในพิกัดโลก จุดสังเกตแต่ละจุดประกอบด้วย x, y และ z: พิกัด 3 มิติในโลกแห่งความเป็นจริงในหน่วยเมตร โดยมีจุดเริ่มต้นที่จุดศูนย์กลางเรขาคณิตโดยประมาณของเข็มนาฬิกา
- multi_handedness : การรวบรวมความถนัดของมือที่ตรวจพบ/ติดตาม ค่า “ซ้าย” หรือ “ขวา”
Pose Landmark Model
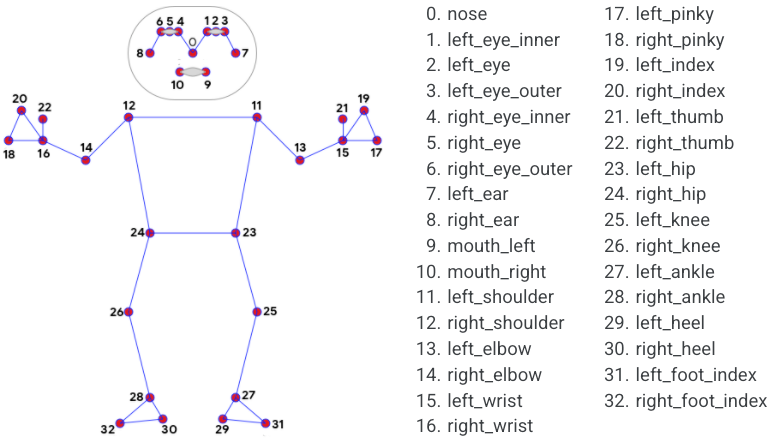
Pose Landmark Model ตรวจจับจุดสังเกตของร่างกายมนุษย์ในรูปภาพหรือวิดีโอ สามารถใช้งานนี้เพื่อระบุตำแหน่งสำคัญของร่างกาย 33 ตำแหน่ง ทำให้วิเคราะห์ท่าทาง และจัดหมวดหมู่การเคลื่อนไหว
ภาษามือที่นำมาใช้
ท่าทางที่นำมาใช้ในโปรแกรมภาษามือประกอบไปด้วย 5 ท่าทาง ได้แก่ ท่านั่ง ท่าเดิน ท่ารอ ท่าหยุด และท่ายืน ส่วนท่ากระโดดนั้นไม่สามารถทำได้เนื่องจากจับภาพยาก และ ท่านี้ Robodog ใช้พลังงานเยอะ จีงไม่เหมาะนำมาทำ
ในส่วนโปรแกรมใช้ภาษา Python และ Library OpenCV กับ Mediapipe โดย OpenCV ใช้ในการประมวลผลรูปภาพและวิดีโอ ส่วน Mediapipe ใช้ในการสร้าง hand landmark model ตามที่อธิบายข้างต้น ดังนั้นวิธีจะแยกท่าทางแต่ละท่าสามารถทำได้โดย การบอกตำแหน่งแต่ละข้อมือ ว่าอันไหนอยู่สูงต่ำ หรือ ขวาซ้าย จึงได้ภาพและวิดีโอตามนี้

ท่านั่ง

ท่ารอ

ท่าเดิน

ท่าหยุด

ท่ายืน
Interface with Robodog
หลังจากนำมาใช้ร่วมกับหุ่นยนต์ ก็พบปัญหาว่ากล้องจับภาพมือทุกตำแหน่งทำให้ Robodog นั้นแสดงท่าทางทุกครั้งเมื่อกล้องจับภาพมือได้ ฉะนั้นจึงได้สร้างพื้นที่ในกรอบสีเขียวเพื่อจับภาพมือ เหตุที่ต้องสร้างกรอบตรงบริเวณหน้าอก เนื่องจากส่วนใหญ่ท่าภาษามืออยู่ระดับหน้าอก
ผลลัพธ์จากการนำไปใช้กับคนร่างกายปกติ
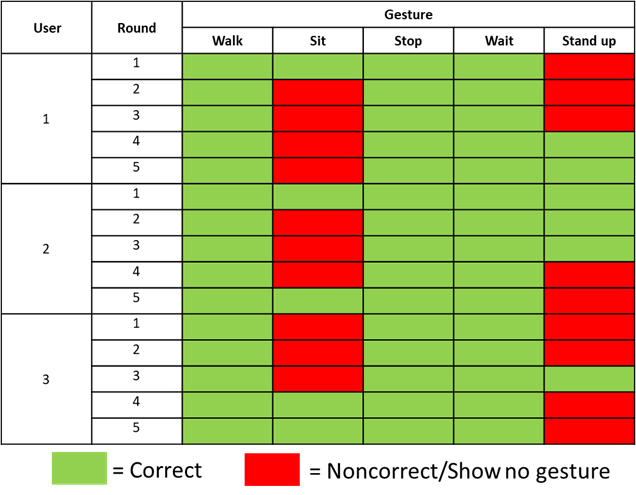
ผลจากการนำไปใช้กับคนร่างกายปกติ แสดงให้เห็นว่า ท่า “WalK” “Stop” และ “Wait” ที่คนร่างกายปกติแสดงท่าทางออกมานั้นทำท่าได้ถูกต้อง 100% แต่กลับกัน “Sit” และ “Stand up” กลับแสดงท่าไม่ถูกต้อง และ บางทีก็ไม่แสดงท่าทาง คิดเป็น 67% และ 60% ตามลำดับ เนื่องจากท่า “Sit” และ “Stand up” เป็นท่าที่ซับซ้อน ทำให้คนร่างกายปกติ อาจแสดงท่าทางไม่ชัดเจน และคนร่างกายปกติพึ่งจะทำเป็นครั้งแรกทำให้แสดงท่าทางผิดถูกบ้าง รวมทั้ง กล้องที่แสดงไม่ต่อเนื่องทำให้มีผลในการจับภาพ
ผลลัพธ์จากการนำไปใช้กับผู้พิการ

System Scenario นี้ได้เพิ่มเติมส่วน Hololens เพื่อ รับค่า Publish จากภาษามือที่ detect จากกล้อง Webcam

พื้นที่ภายในกรอบสีเขียวคือ พื้นที่แสดงภาษามือ เพื่อสั้งท่าทาง Robodog โดยกรอบนี้อยู่นิ่งทำให้กล้องสามารถ detect ภาพ ได้ดีกว่ากรอบที่ติดตามระดับหน้าอก

ผลจากการนำไปใช้กับผู้พิการแสดงให้เห็นว่า ท่าทาง “WalK” “Stop” และ “Wait” ที่ ผู้พิการแสดงท่าทางออกมานั้นทำท่าได้ถูกต้อง 100% แต่กลับกัน “Sit” และ “Stand up” กลับแสดงท่าไม่ถูกต้อง และ บางทีก็ไม่แสดงท่าทาง คิดเป็น 50% และ 83% ตามลำดับ เนื่องจากท่า “Sit” และ “Stand up” เป็นท่าที่ซับซ้อน อีกทั้งผู้พิการคนที่ 1 มีอาการแขนขาอ่อนแรง ทำให้แสดงท่าไม่ถูกต้องเต็มรอย แต่เมื่อปรับให้มีพื้นที่แสดงภาษามือที่ชัดเจน (กรอบสีเขียว) ทำให้กล้องแสดงภาพได้ต่อเนื่อง และจับภาพได้ดีกว่า การกำหนดพื้นที่ติดตามระดับหน้าอกในการทดสอบกับคนร่างกายปกติ
*เกิดเหตุขัดของ Robodog ทำให้ไม่สามารถเก็บผลการทดลองต่อกับผู้พิการคนที่ 2 ได้
Reference
- https://hcilab.net/class-project/fra-641-computer-programming-for-robotics/2023/10/06/class-project-robodog/
- https://developers.google.com/mediapipe/solutions/vision/hand_landmarker
- https://developers.google.com/mediapipe/solutions/vision/pose_landmarker/
ส่วนขยายเพิ่มเติม
ผู้จัดทำ

ณรงค์รัชช์ อู่สิริมณีชัย รหัสนักศึกษา 65340700403